구축형 chatgpt(ollama-open-webui) for rocky 9.5
docker 에 ollama + webui 에 llm 올리는 방식이다.
그래픽카드 설치 하고 안해도 되긴 하는데 답변이 너무 느리다.
링크 참조
# dnf install -y dnf-plugins-core
# dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
# dnf install -y docker-ce docker-ce-cli containerd.io
# systemctl enable --now docker
# usermod -aG docker $USER
# DOCKER_COMPOSE_VERSION=$(curl -s https://api.github.com/repos/docker/compose/releases/latest | grep tag_name | cut -d '"' -f 4)
# curl -L "https://github.com/docker/compose/releases/download/${DOCKER_COMPOSE_VERSION}/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
# chmod +x /usr/local/bin/docker-compose
# ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
# docker-compose version
Docker Compose version v2.35.0
정상 설치 다 됐으면
# mkdir -p /data/ollama
# cd /data/ollama
# vi docker-compose.yaml
services:
ollama:
image: ollama/ollama
container_name: ollama-ollama
ports:
- "11434:11434"
volumes:
- ollama:/root/.ollama
environment:
- NVIDIA_VISIBLE_DEVICES=all
- NVIDIA_DRIVER_CAPABILITIES=compute,utility
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: ollama-open-webui
ports:
- "3000:8080"
volumes:
- open_webui:/app/backend/data
environment:
- OLLAMA_BASE_URL=http://ollama:11434
depends_on:
- ollama
volumes:
ollama:
open_webui:
위 내용 추가 후 저장
# docker-compose up -d
구동
만약에 멈추고 중단하고 싶다면
# docker-compose down
구동후에 브라우저로 접속
http://localhost:3000

get started 눌러서
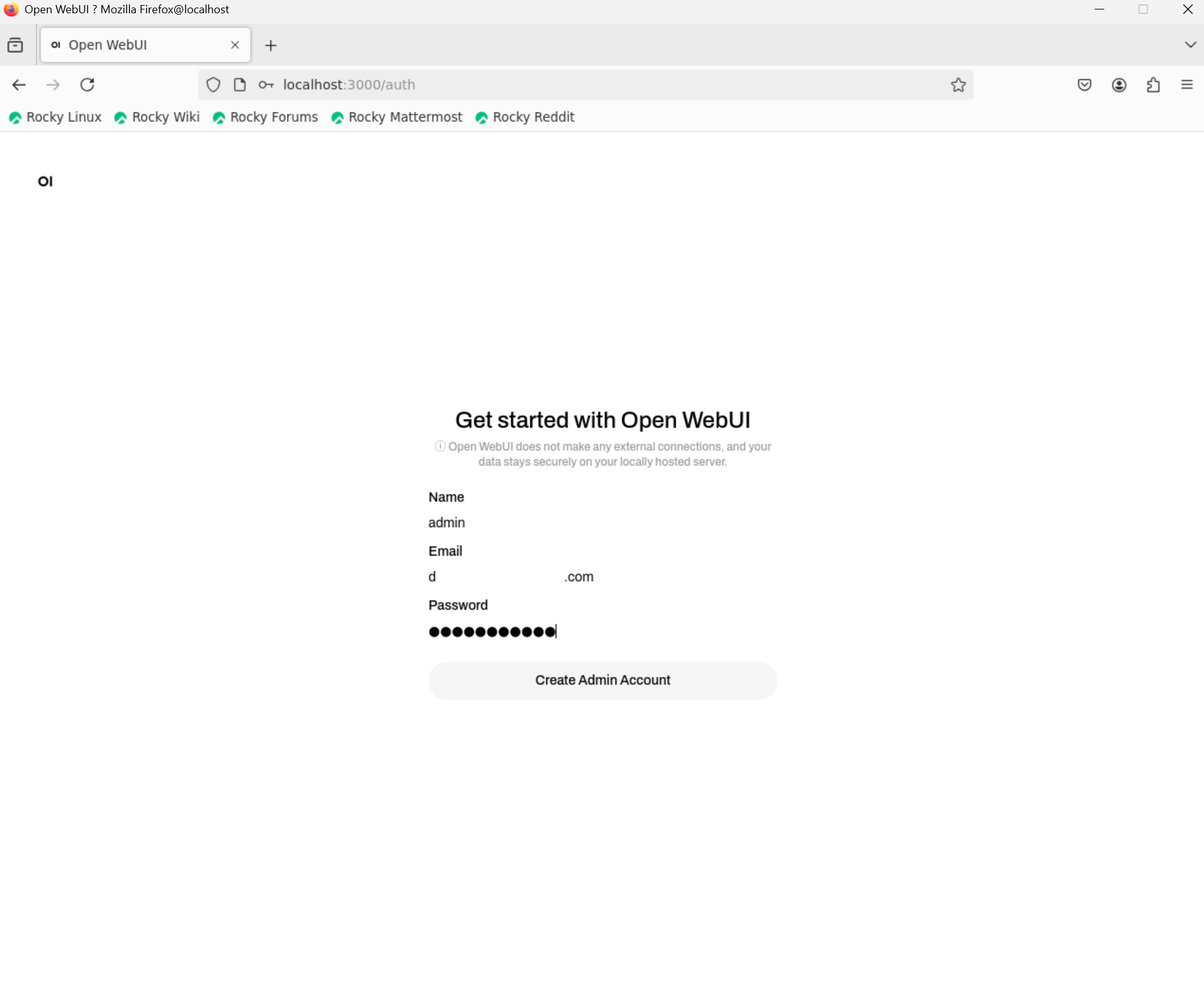
계정 만들고
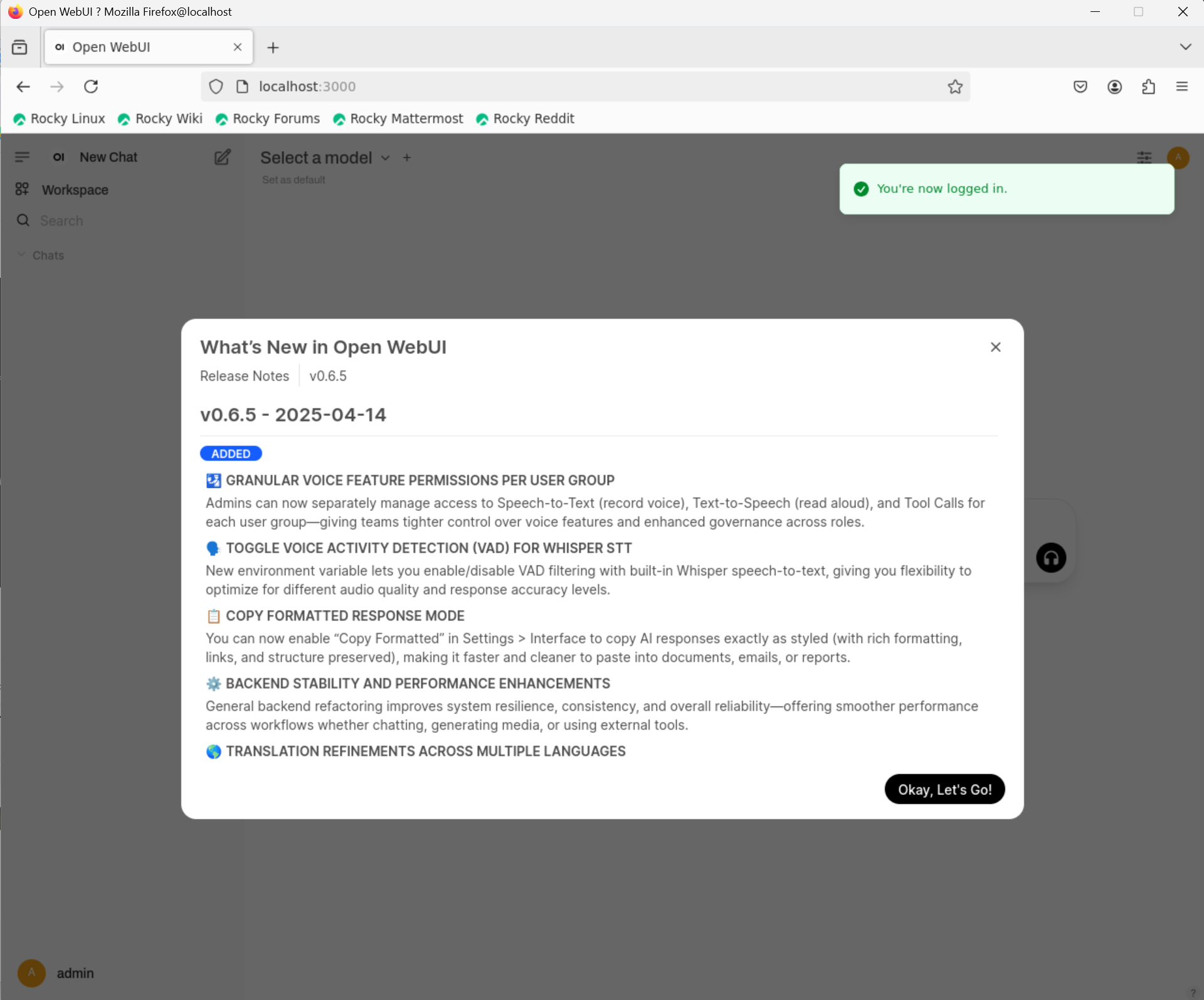
로그인 하면
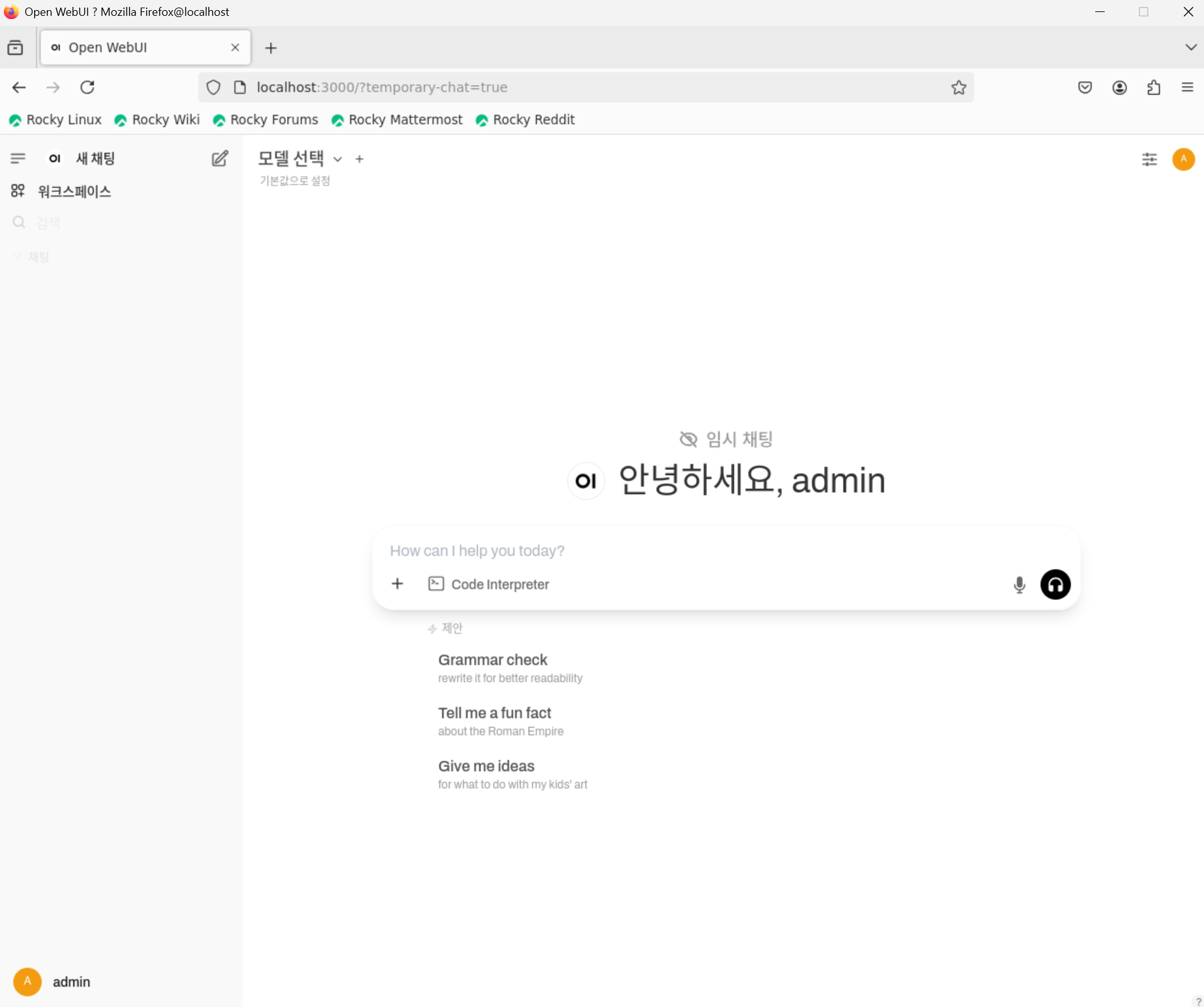
chatgpt 처럼 ui 가 나온다. 지금은 모델이 없어서 모델을 추가 하자.
# docker exec -it ollama-ollama ollama pull llama3
# docker exec -it ollama-ollama ollama pull mistral
# docker exec -it ollama-ollama ollama pull openhermes
보통 3가지가 유명하니 추가하자
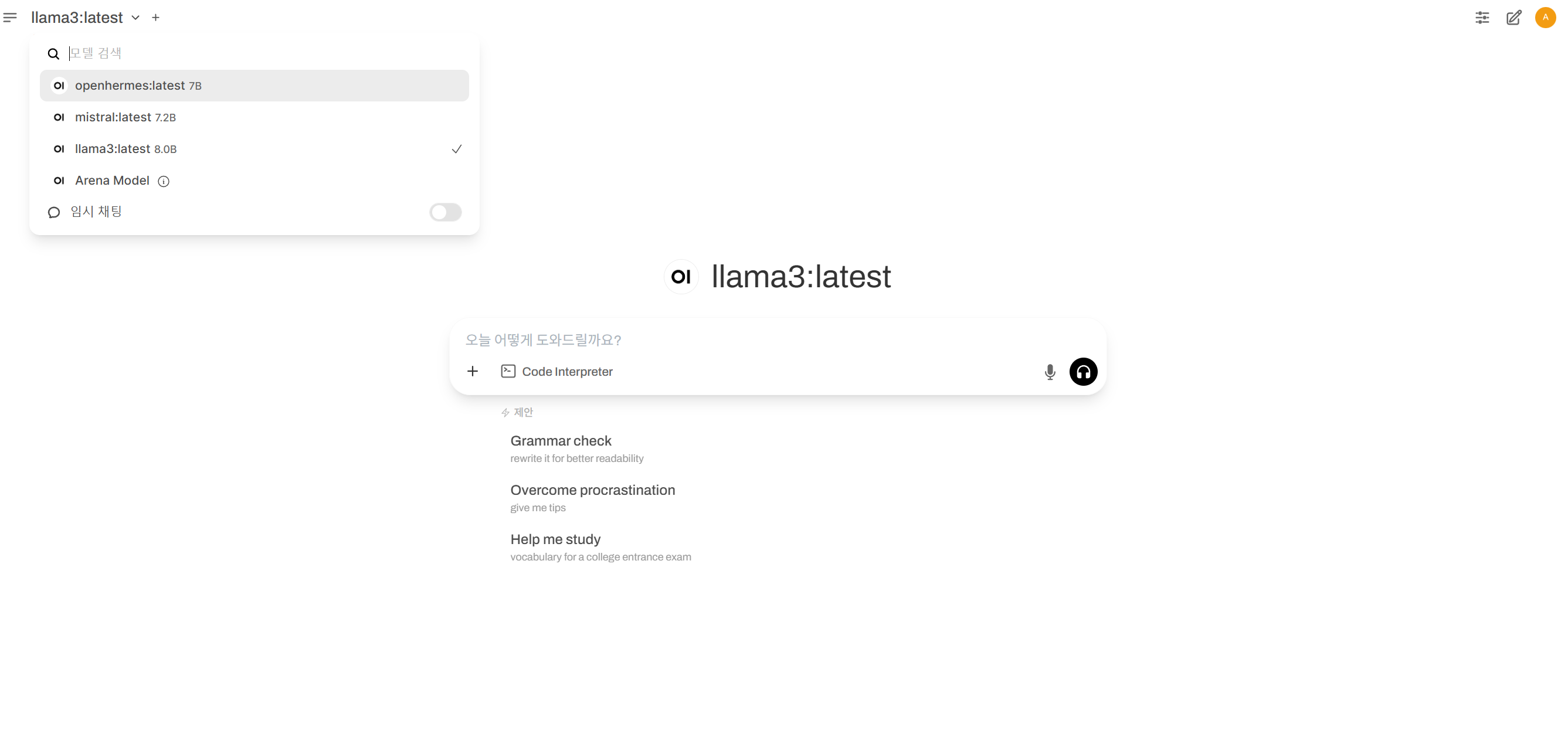
정상적으로 추가 되었다.
만약에 답변이 느리면 docker 에 nvidia 가 정상적으로 로드가 안되서 그렇다. 추가 작업은
NVIDIA Container Toolkit 설치해줘야 하고
# distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
# curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.repo | sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repo
# dnf install -y nvidia-container-toolkit
이렇게 하면 설치가 되고 정상 작동 되는것 확인하려면
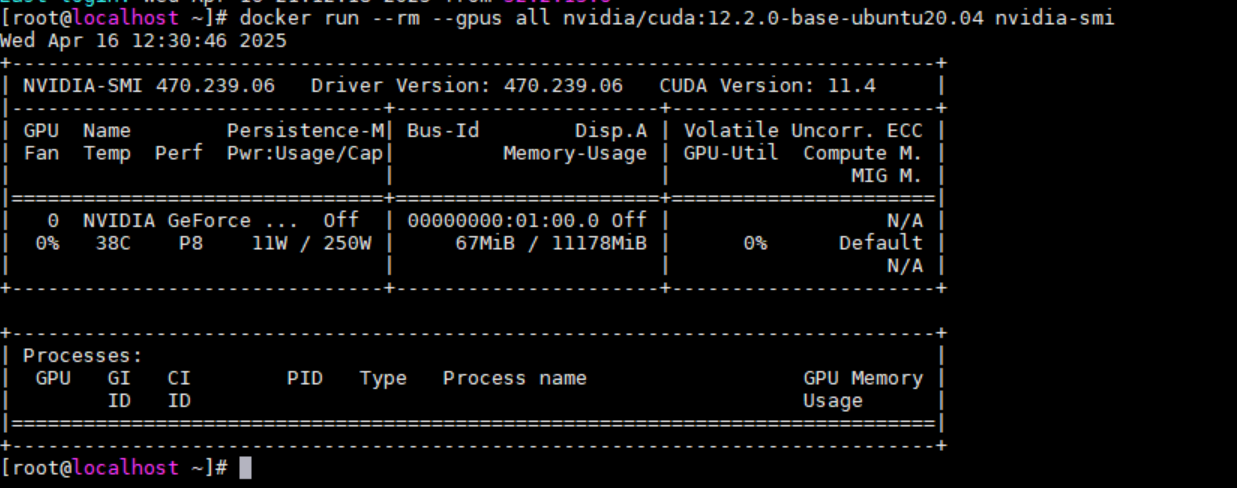
정상적으로 인식된게 확인이 된다. 자 이제 사용해보자!
그리고 설치한 모델은
# docker exec -it ollama-ollama ollama list

로 확인 가능하고 삭제는
# docker exec -it ollama-ollama ollama rm llama3

'Linux' 카테고리의 다른 글
| lmstudio install for rocky 9.5 (2) | 2025.05.01 |
|---|---|
| 83:00.0 Ethernet controller: Realtek Semiconductor Co., Ltd. RTL8125 2.5GbE Controller (rev 0c) rocky 8.x install (1) | 2025.04.30 |
| 1080ti cuda install for rocky 9.5 (1) | 2025.04.20 |
| nvidia install for rocky 9.5 with 1080ti (2) | 2025.04.18 |
| websvn install for rocky 8.x(viewvc대체) with dnf install websvn (1) | 2025.03.02 |